What is This?
VAE(とAE)の中間層の状態を見てみたいなと思い、可視化してgifにしました.
以前からVAEでmnistの複数の数字を入れたらわかりにくいと感じていたので、1文字で学習させています.
可視化コードを加えただけですが「コード」のタブにソースコードを置いておきました. 使いまわせる方がいると幸いです.
gifにはImageMagickをインストールして以下でgif化
下記では、全て中間層(隠れ層)を2次元にしています.
VAE Visualize Results
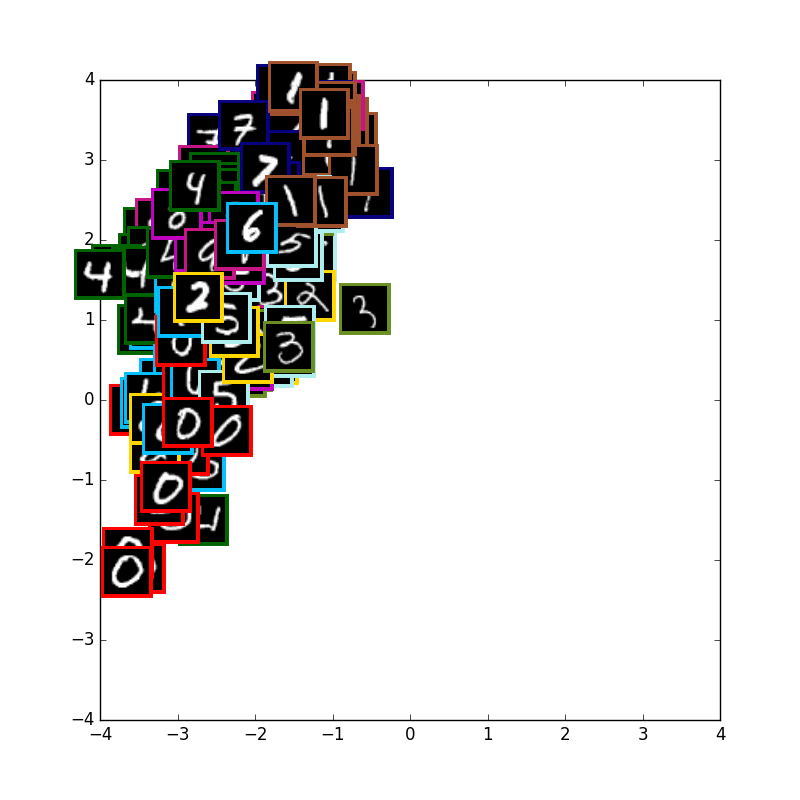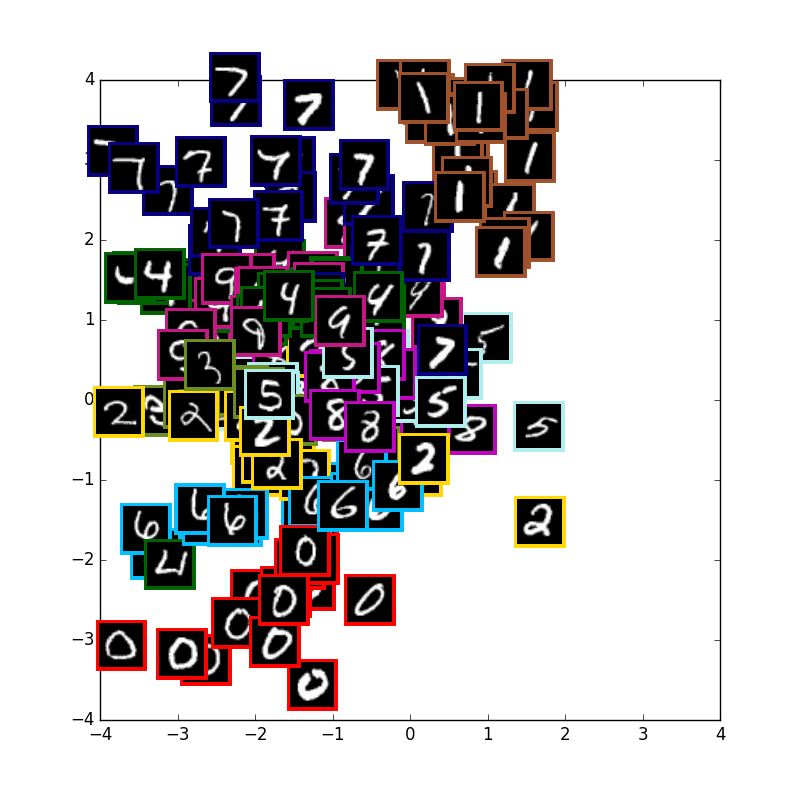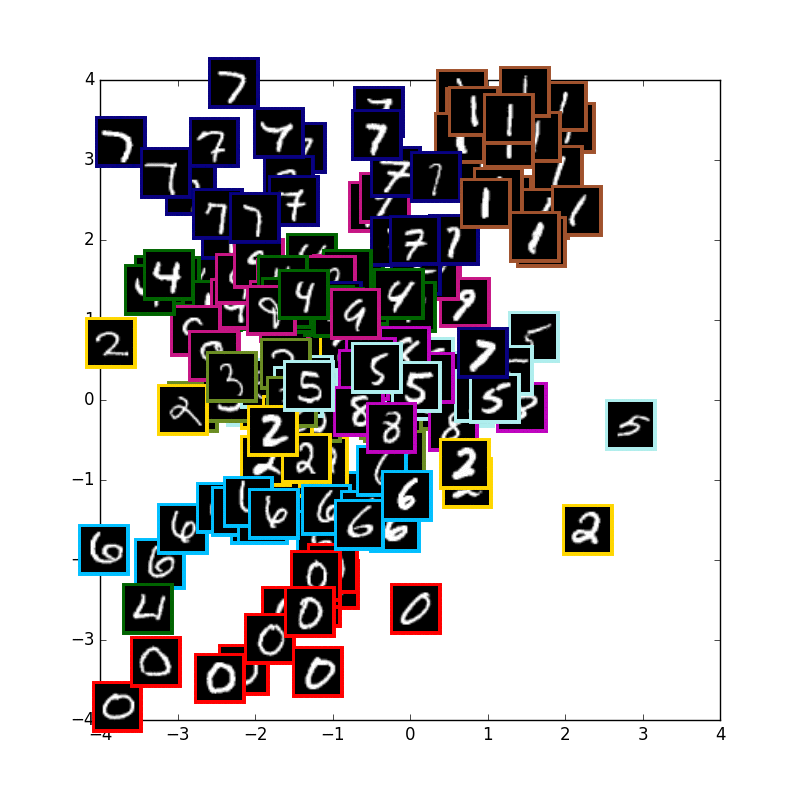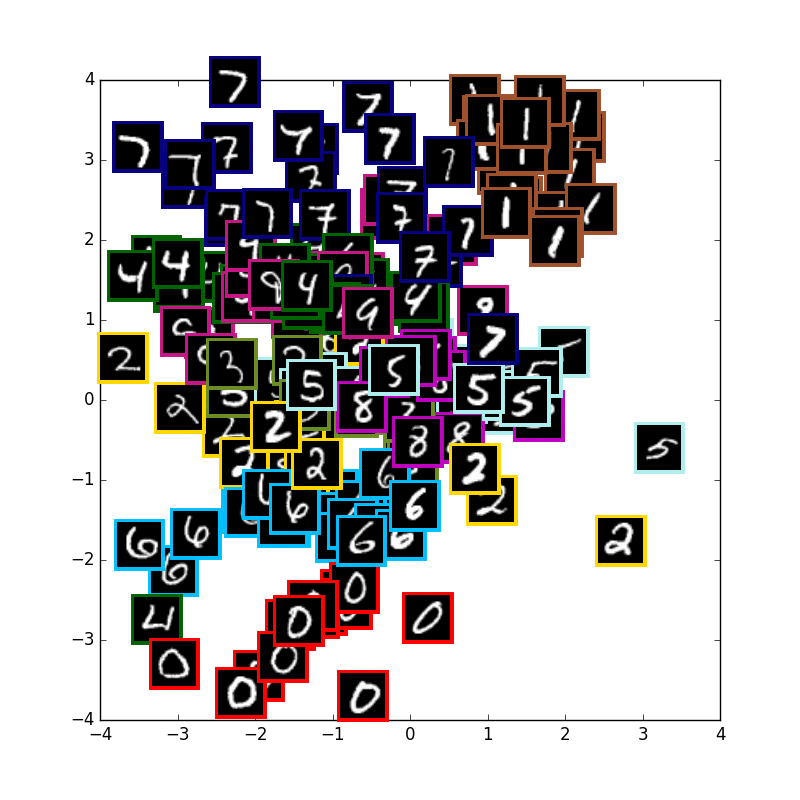
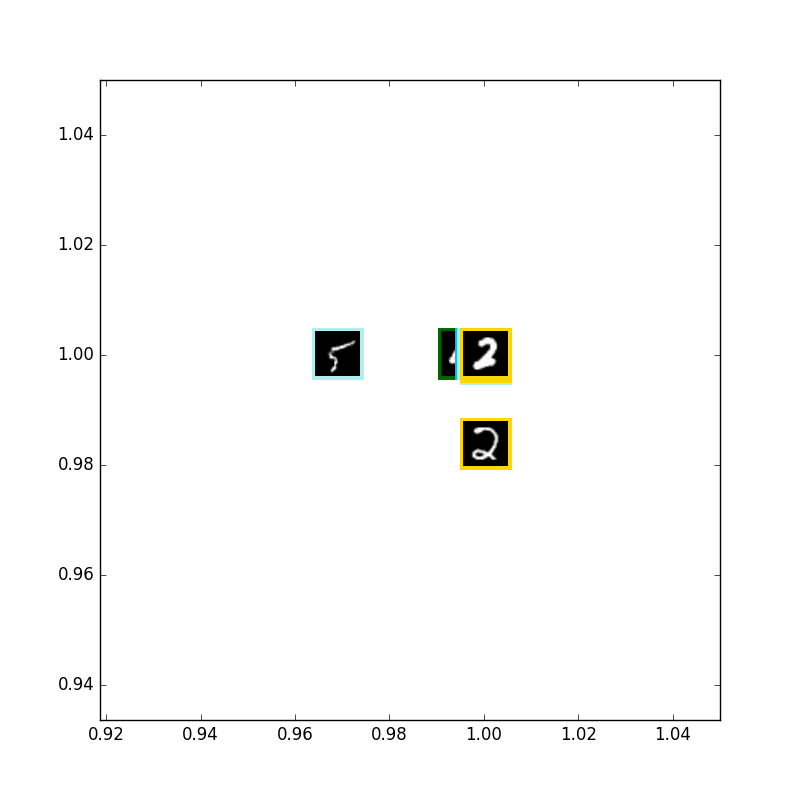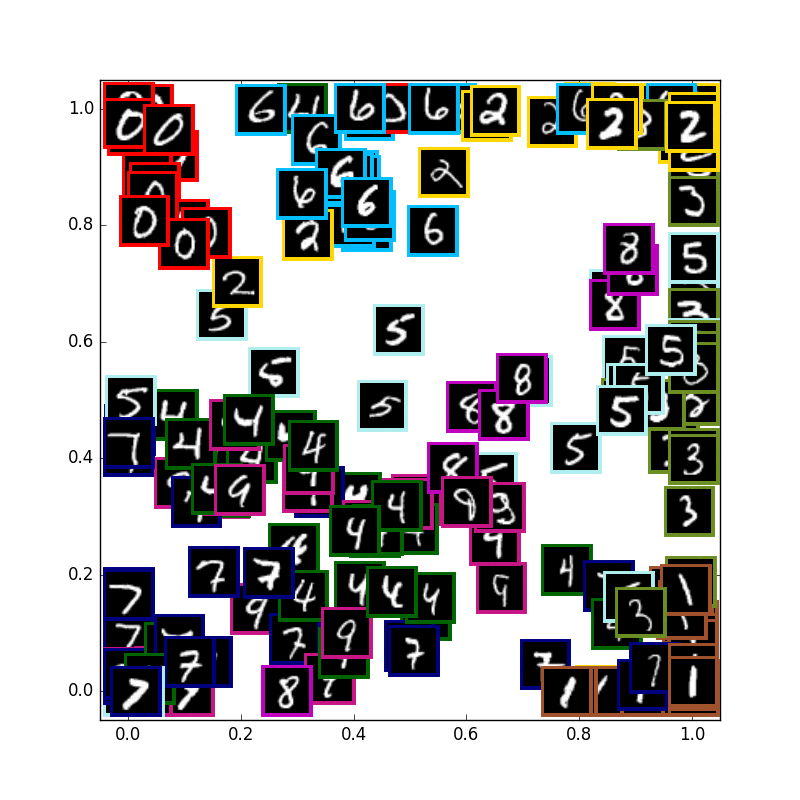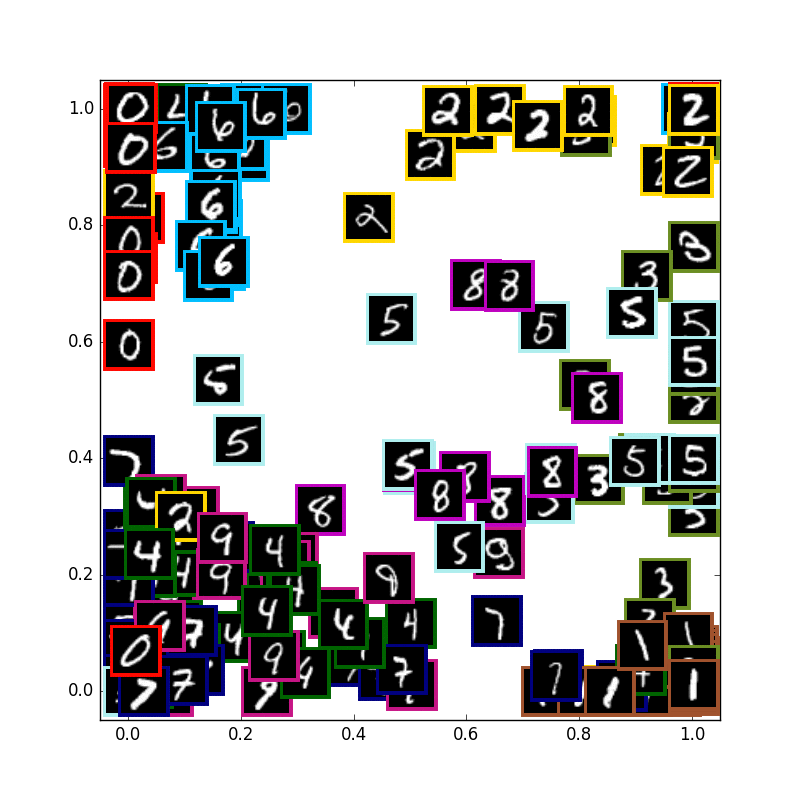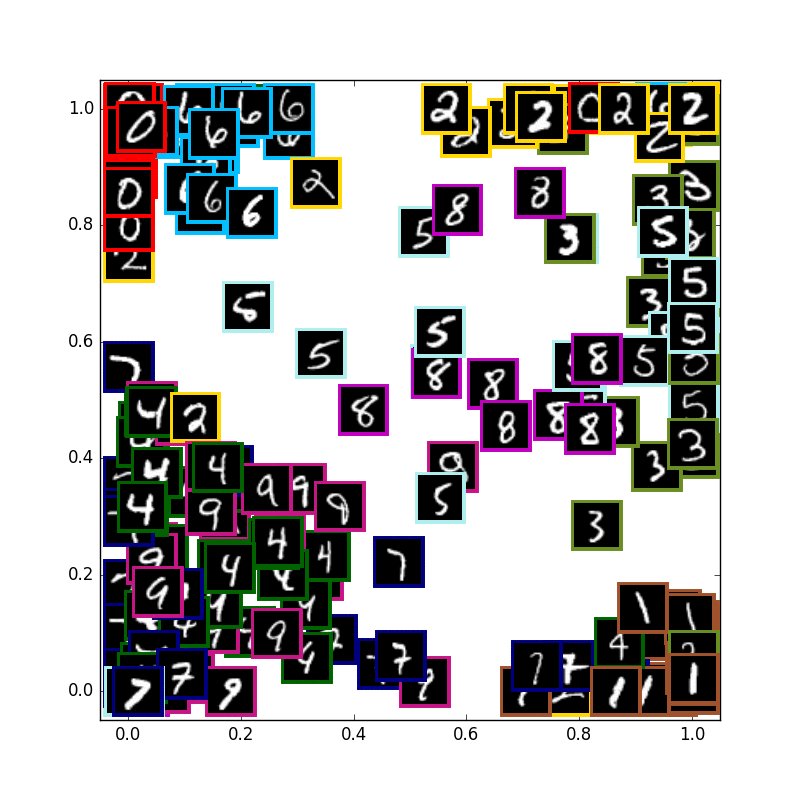
VAE with 10 digits
まずは通常の10種類のmnistの学習です.少しずつ真ん中に全体の山が寄って行きます.
可視化に使用している画像はテストデータで学習には使用していません.
VAE with 1 digits
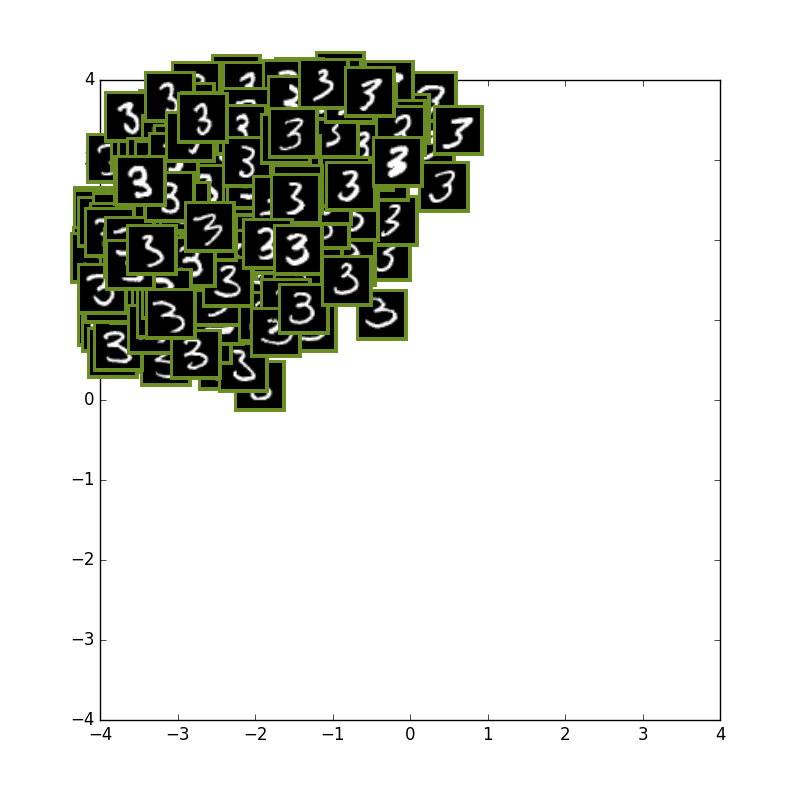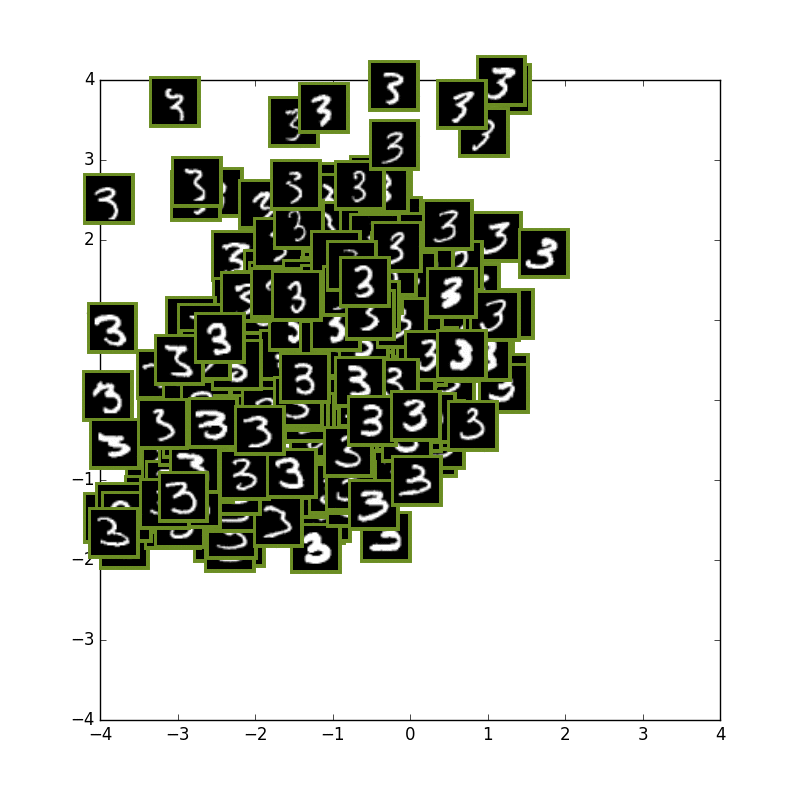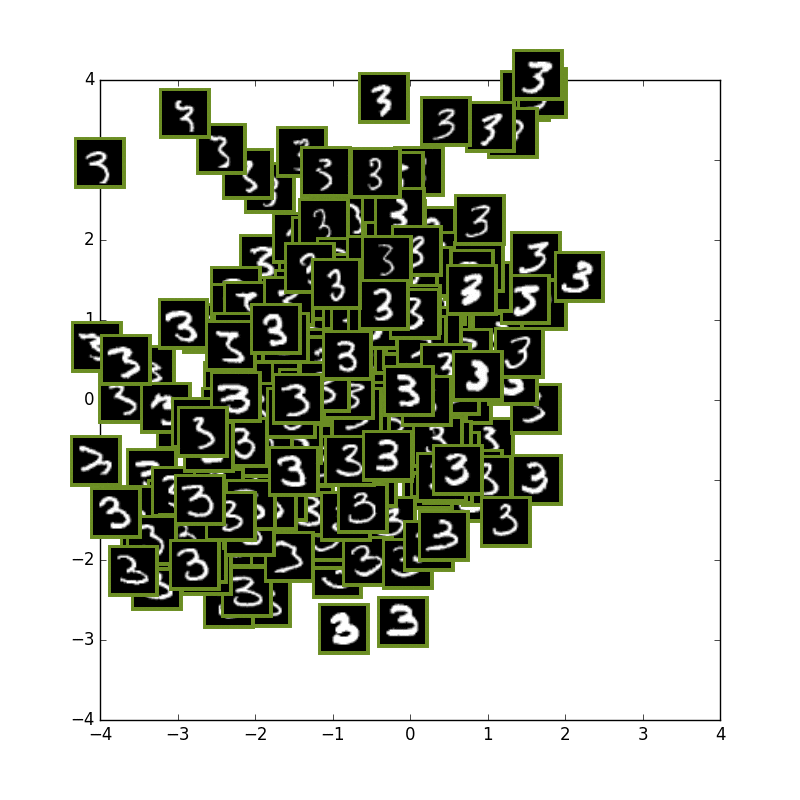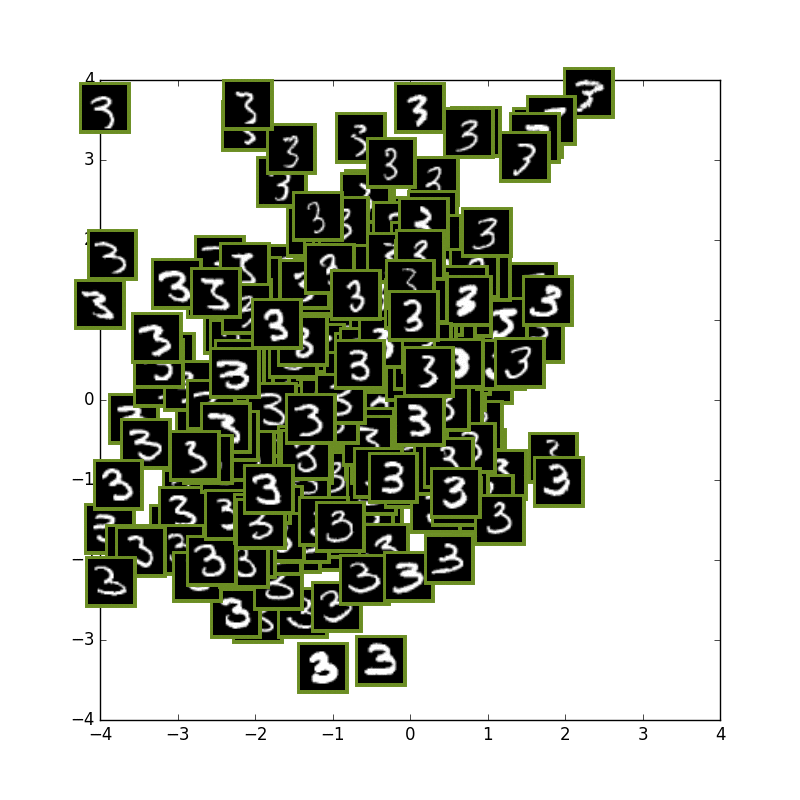
次に数字の3の学習だけを行い、テスト画像にも3の数字だけを入力しています.
こころなしか周辺にあまりお目にかからない崩れた3が来ていて、真ん中にはよくみる3が来ているように見えなくもない...
全体的にガウス分布になろうとしている感じがあります.
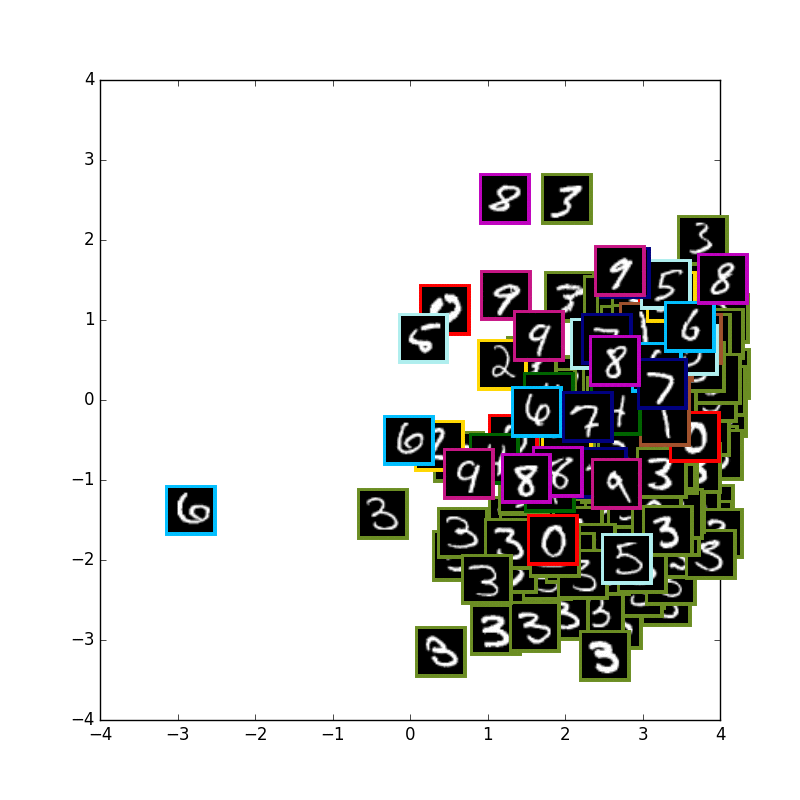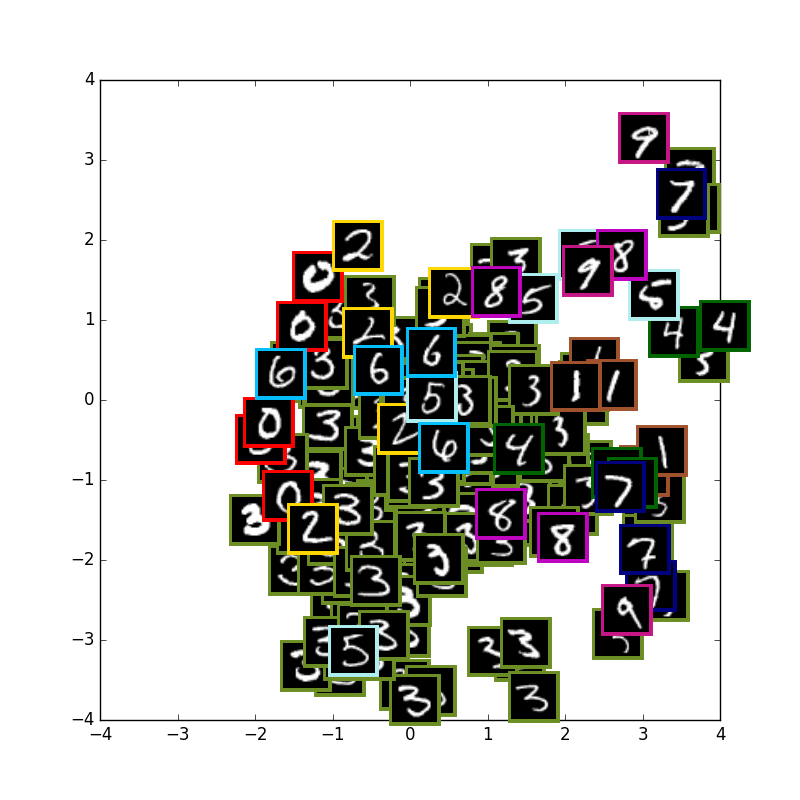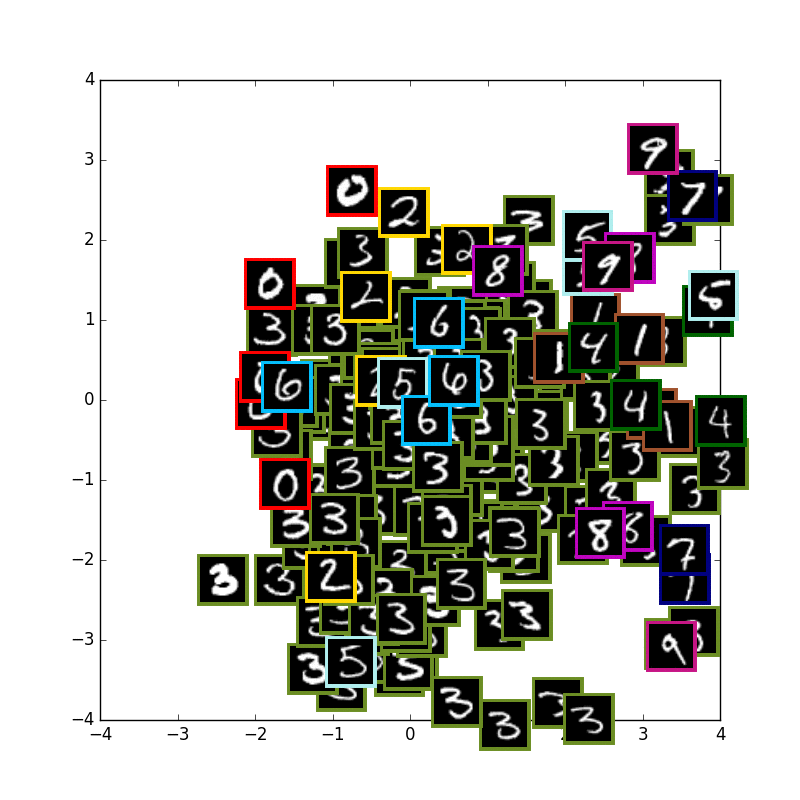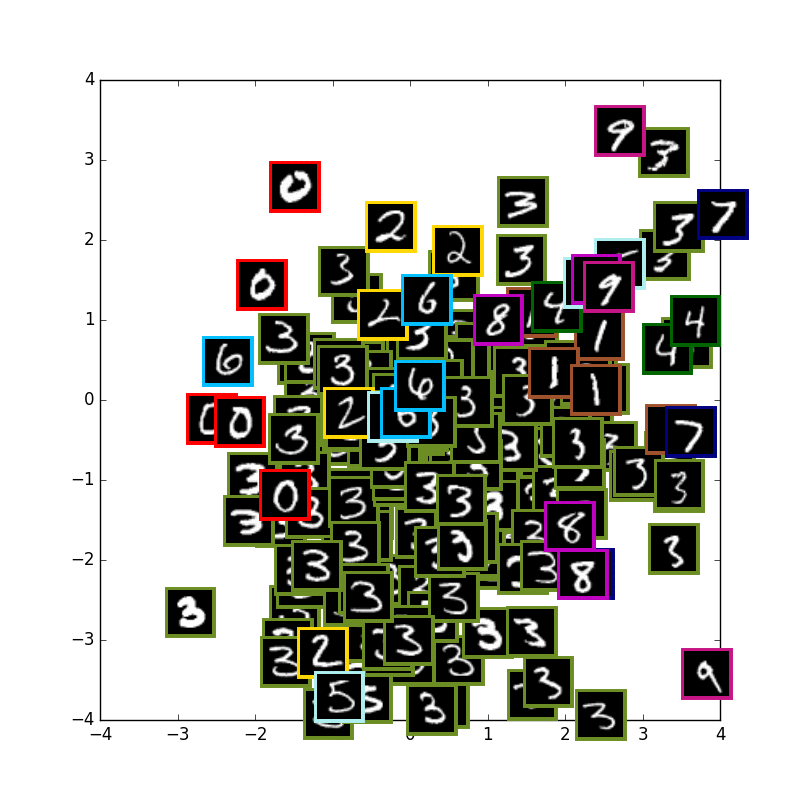
VAE with 1 digits & other digits
次に数字の3の学習だけを行い、テスト画像には3の数字と他の数字も入力として入れてみてます.
私の期待では,3以外の数字は全て外側に来て内側は3しかない状態になることを思い描いていましたが
やはり潜在変数2が少なすぎるせいかそこまで上手くは行きませんでした...
2とか6とかがやや侵入してきています.
AE Visualize Results
AE with 10 digits
まずは通常の10種類のmnistの学習です.0~1の間に収まっているのはsigmoidのおかげです.
ReLuにしているものをあまり見かけなかったのでここのままにしています.
AE with 1 digits (FAIL)
次に3だけにしましたが、どうも上手く学習されなくなった気がします.
原因はまだ調べているところです.特にできなくなる理由は見つからない気がするのですが...
コードの大部分はaymericdamienさんのコードをベースにしています.
Gist等含めて右UrusuLambda's Github
Code (VAE just visualize 2d hidden layer. Multiple Digits)
10種類のMNISTをVAEで学習させているときのコードです.元のコードに可視化用のコードを加えて、中間層から値を取得して2Dにプロットしています.
Code (VAE just visualize 2d hidden layer. Single Digits)
1種類のMNISTをVAEで学習させているときのコードです.(大して一つめと変わりません)
Code (AE just visualize 2d hidden layer. 10 Digits)
10種類のMNISTをAEで学習させているときのコードです.(大して一つめと変わりません)